GLM-OCR: A 0.9B Model That Runs Locally and Extracts Structured Data from Complex Documents
GLM-OCR is a 0.9B multimodal OCR model from Z.ai with day-0 vLLM and MLX-VLM support. Runs locally, extracts structured JSON from invoices, tables, and formulas.

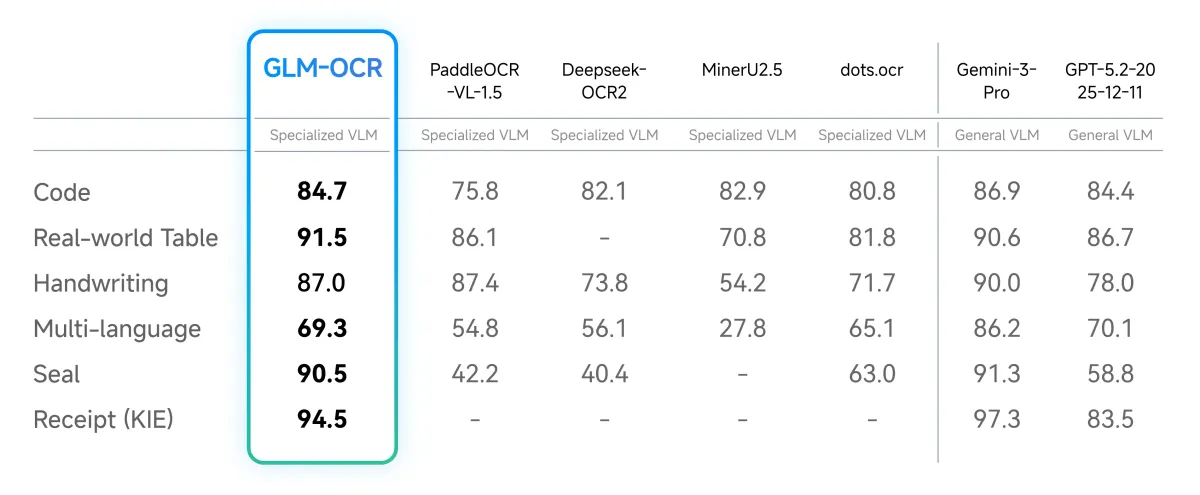
A 0.9B parameter model doing invoice parsing, formula extraction, and structured JSON output well enough — and both vLLM and MLX-VLM shipping day-0 support on launch day — is the kind of signal that's hard to dismiss as hype.
GLM-OCR, released by Z.ai (Zhipu AI) as fully open source, is a multimodal model purpose-built for complex document understanding. It handles text recognition, table parsing, formula extraction, and Key Information Extraction (KIE) from structured documents like invoices, forms, and scanned PDFs. The model weighs in at just 2.65GB on disk and consumes roughly 2.5GB of VRAM at inference time — meaning it runs comfortably on a modern consumer GPU, or even a capable CPU.
That's the practical headline. Not "Z.ai releases OCR model," but: you can pull this locally today, point it at an invoice, and get back a properly structured JSON object in seconds, without sending anything to a cloud API.
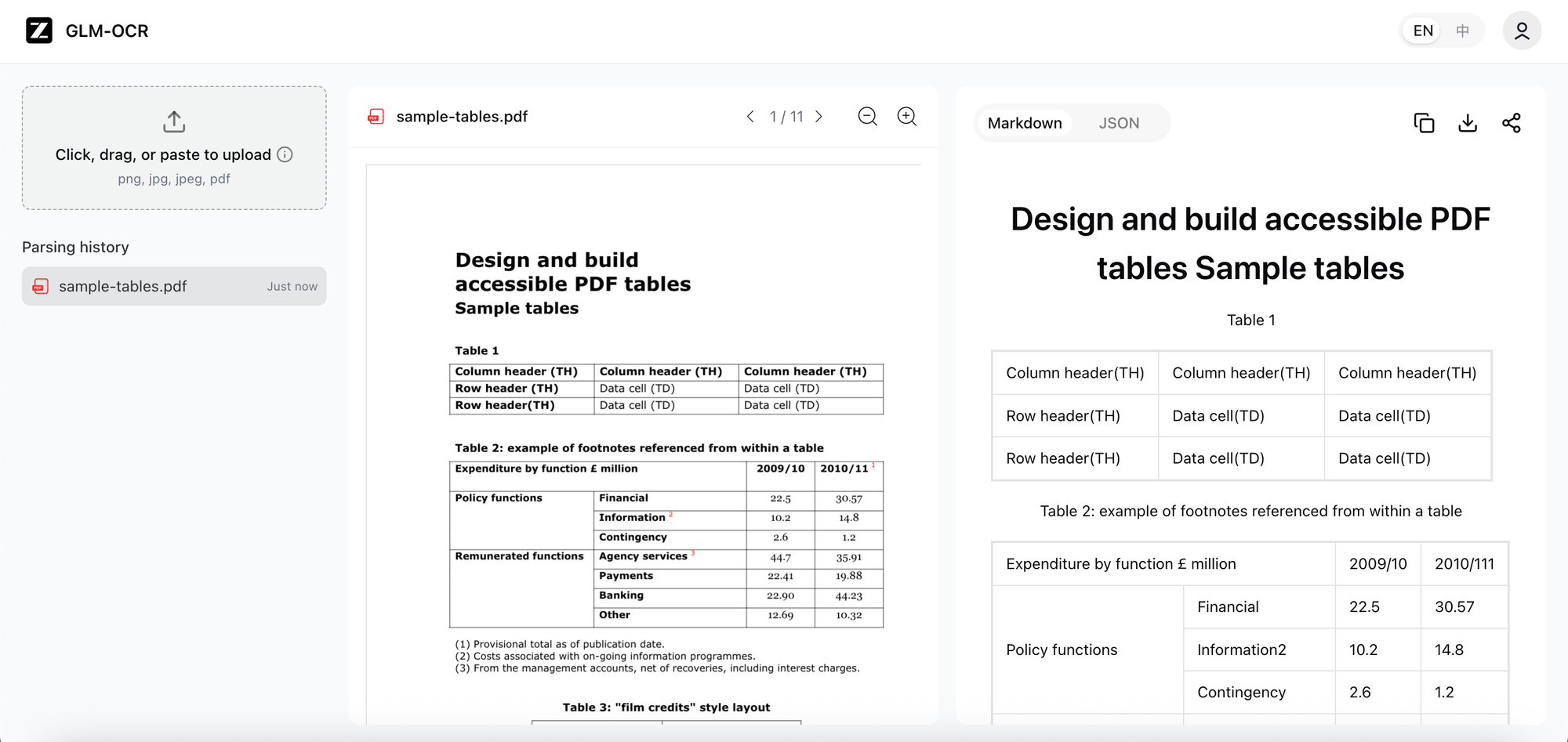
What It Actually Does
GLM-OCR supports two distinct task modes. The first is raw content extraction — pulling text, tables, and LaTeX-formatted formulas from document images. The second is KIE: Key Information Extraction, where you pass a JSON schema and the model fills it with values pulled from the document.
In practice, the KIE mode is the more interesting one. You define the fields you want — invoice number, line items, totals, dates — and the model returns a JSON object matching your schema. Early testing from people running it locally confirms the output stays on-schema and the field values are accurate. This is the use case that makes cloud document APIs like AWS Textract or Google Document AI nervous, not vanilla OCR.
The architecture is a three-part encoder-decoder: a CogVLM visual encoder pretrained on large-scale image-text data, a lightweight cross-modal connector that downsamples visual tokens, and a GLM 0.5B language model as the text decoder. The model is trained with multi-token prediction loss and reinforcement learning over full tasks, which Z.ai says improves both training efficiency and recognition accuracy.
The two-stage pipeline — layout analysis first, then parallel recognition — means it can handle mixed-layout documents that would trip up traditional OCR systems. Tables aren't read as flat text; they're recognized as structured grids with headers, rows, and columns.
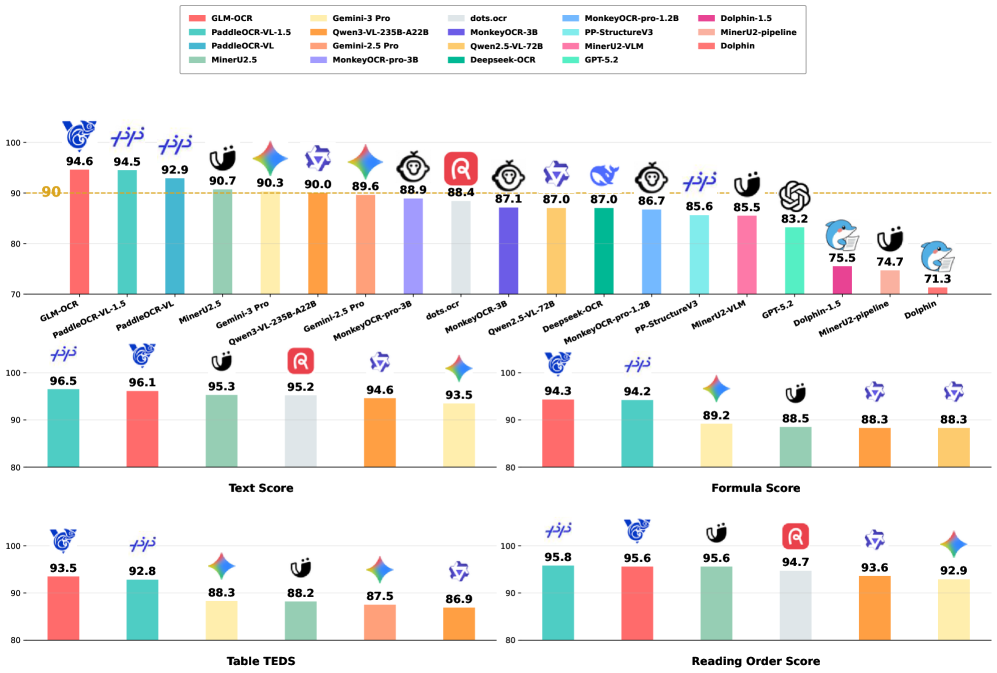
Day-0 Ecosystem Support
This is where GLM-OCR's launch stands out from a typical open-source model drop. Both vLLM and MLX-VLM had support ready on day one — and that's not a coincidence.
Getting both frameworks to ship same-day support requires pre-launch coordination. Z.ai clearly worked with ecosystem partners before the release — a level of go-to-market execution that's been unusual for Chinese open-source labs but is becoming a pattern. Prince Canuma's note that quantized weights were already on the Hub at launch, but MLX-VLM still required a source install, is a minor friction point worth flagging if you're on Apple Silicon today.
The model is also compatible with Ollama, SGLang, and direct Python inference via HuggingFace Transformers. The official documentation covers all deployment paths. A live demo runs at ocr.z.ai.
Real Limitations, Not Fine Print
GLM-OCR is bilingual — English and Chinese only. Testing on Hindi, Arabic, Polish, and French shows the model either produces gibberish or hangs indefinitely. That's a hard constraint, not a soft "limited support" caveat. If your document pipeline handles European or Middle Eastern languages, this isn't the right tool yet.
The model also lacks third-party benchmark validation at this point — Z.ai describes it as "industry-leading" in character recognition, but independent benchmark results are still sparse. The Hacker News thread (302 points, 75 comments) reflects genuine developer interest, but the mild skepticism around unverified SOTA claims is fair. The performance is real; the ranking relative to every competitor is still being sorted out.
One more thing: GLM-OCR missed an apostrophe in a handwritten letter test, and occasionally stumbled on cursive edge cases. For clean printed documents and structured forms, accuracy looks solid. For handwritten documents with unusual formatting, results are more variable.
Teams running simple, single-column printed text through existing pipelines — Tesseract, EasyOCR — probably don't need to switch. This model earns its place specifically in mixed-layout document parsing: invoices with tables, academic PDFs with formulas, ID cards with structured fields. If that's not your use case, the upgrade isn't worth the operational overhead of self-hosting.
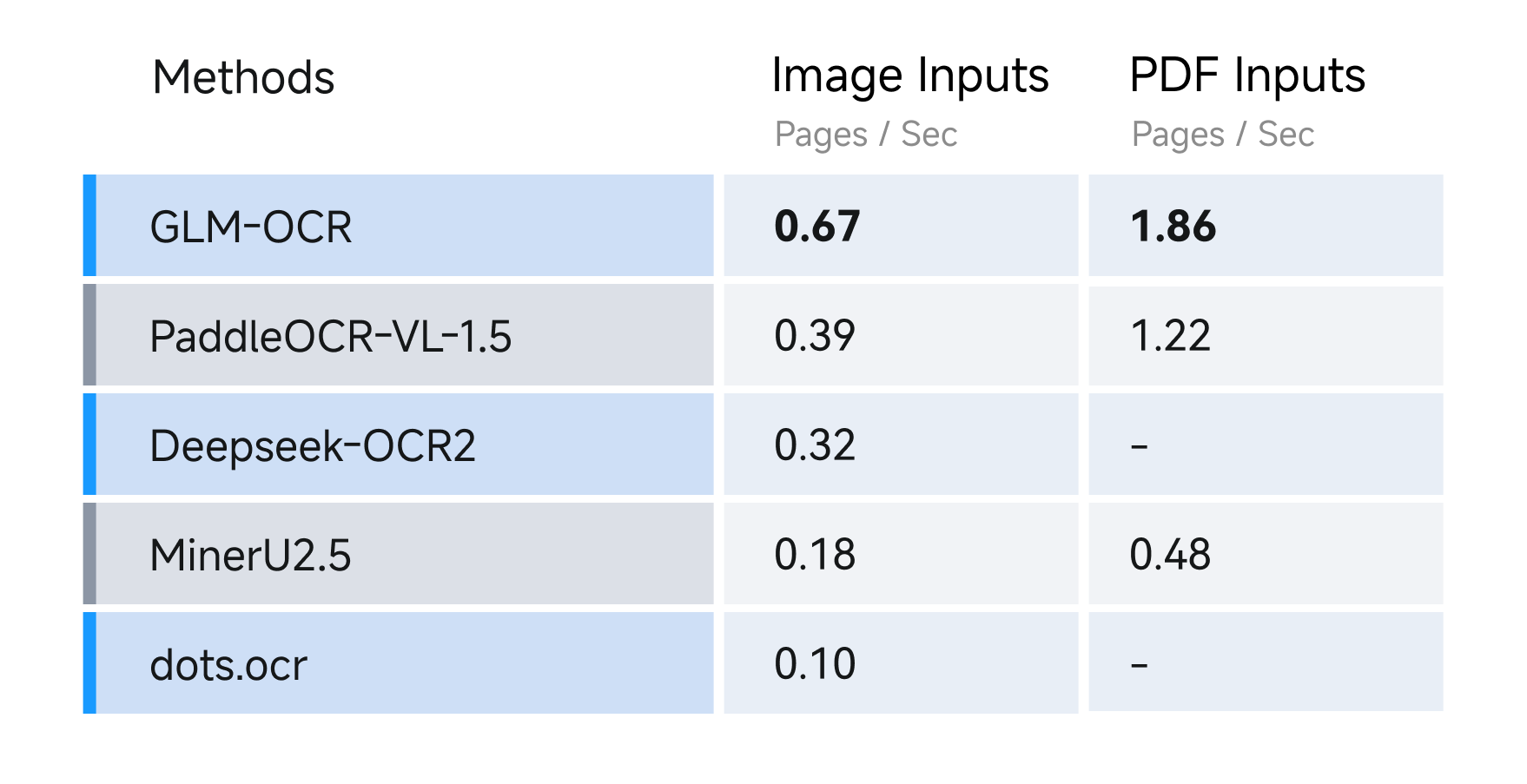
Context: Z.ai's Broader Open-Source Push
GLM-OCR isn't an isolated release. Z.ai has also recently shipped GLM-4.6V, a native tool-calling vision model, and GLM-4.7-Flash, a 30B MoE model targeting coding and agents. These aren't all the same model in different clothes — it's a specialized model family strategy: task-specific small models rather than one massive general-purpose model.
That's arguably the smarter open-source play in 2026. A 0.9B model trained tightly for document OCR will beat a 70B general model on invoice parsing, cost a fraction of the compute, and run on hardware your team already has. This is the same logic behind Microsoft's BitNet work — task efficiency over raw parameter count.
The competitive pressure from Chinese labs — Z.ai, Qwen, MiniMax — releasing capable open-source models in rapid succession is real, and GLM-OCR is part of that wave. But unlike releases that are interesting mainly because of the source, this one has a specific, practical use case that makes evaluation straightforward: either it can parse your documents accurately, or it can't.
Getting Started
Model weights are on HuggingFace under the zai-org organization. For production serving, vLLM is the cleanest path. For local Apple Silicon inference, install MLX-VLM from source for now — packaged release is coming. For quick testing, the demo at ocr.z.ai requires no setup.
The clearest way to evaluate whether GLM-OCR belongs in your stack: take five of your hardest documents — the ones with tables, mixed layouts, or embedded formulas — and run them through the demo. If it handles those, the rest will be easy. If it stumbles, you have your answer before writing a single line of deployment code.
The language constraint is the one real blocker. Watch whether Z.ai extends support beyond English and Chinese — if that changes, the addressable use case for this model expands considerably.
Links:
https://huggingface.co/zai-org/GLM-OCR
https://github.com/zai-org/GLM-OCR
https://ocr.z.ai/