Hume AI Releases TADA: Its First Open-Source Text-to-Speech Model
Hume AI has open-sourced TADA, a fast text-to-speech model with near-zero hallucinations and long-context support. Here's what it does and why it matters.


- TADA (Text-Acoustic Dual Alignment) is Hume AI's first open-source text-to-speech model, released March 10, 2026.
- It syncs text and audio one-to-one, which makes it significantly faster and more reliable than comparable LLM-based TTS systems.
- In testing on 1,000+ samples, TADA produced zero hallucinations — meaning it never skipped, inserted, or garbled words.
- It can handle roughly 700 seconds of audio within the same context budget that competing systems exhaust in about 70 seconds.
- Both the models and source code are publicly available now for researchers, developers, and companies building voice applications.
TATA TTS Demo
What Is TADA?
TADA stands for Text-Acoustic Dual Alignment. It's a new text-to-speech (TTS) system from Hume AI that converts written text into natural-sounding spoken audio — and it does so in a way that's meaningfully different from how most current TTS systems work.
Most LLM-based TTS systems struggle with a basic mismatch: for every second of audio, there are far more audio frames than there are text tokens. Think of it like trying to pair up a short shopping list with a long grocery store receipt — the numbers just don't line up cleanly. That mismatch leads to slower performance, higher memory use, and a tendency for the model to lose track of what it was supposed to say.
TADA solves this by doing something different: instead of compressing audio into fewer frames or adding extra "middleman" tokens, it aligns each text token directly to exactly one audio vector. Text and speech move through the model in perfect lockstep.
Try the model: https://t.co/kY2sSifaXq
— Hume AI (@hume_ai) March 10, 2026
How the Architecture Actually Works
In a standard LLM-based TTS system, a single second of audio might require 12.5 to 75 audio tokens — but only 2 or 3 text tokens. The model has to manage a sequence where audio tokens wildly outnumber text tokens. That creates longer context windows (how much the model can hold in memory at once), slower inference, and more chances for errors.
TADA flips this by using a continuous acoustic vector per text token instead of discrete, fixed-rate audio frames. Each step through the language model corresponds to exactly one text token and exactly one audio frame — no more, no less.
On the input side, an encoder and aligner extract acoustic features from the audio segment that matches each text token. On the output side, the model's final hidden state conditions a flow-matching head (a generation technique that gradually refines audio output) to produce the corresponding audio, which is then decoded and fed back into the model.
Because the architecture enforces a strict one-to-one mapping, the model cannot skip or hallucinate content by design.
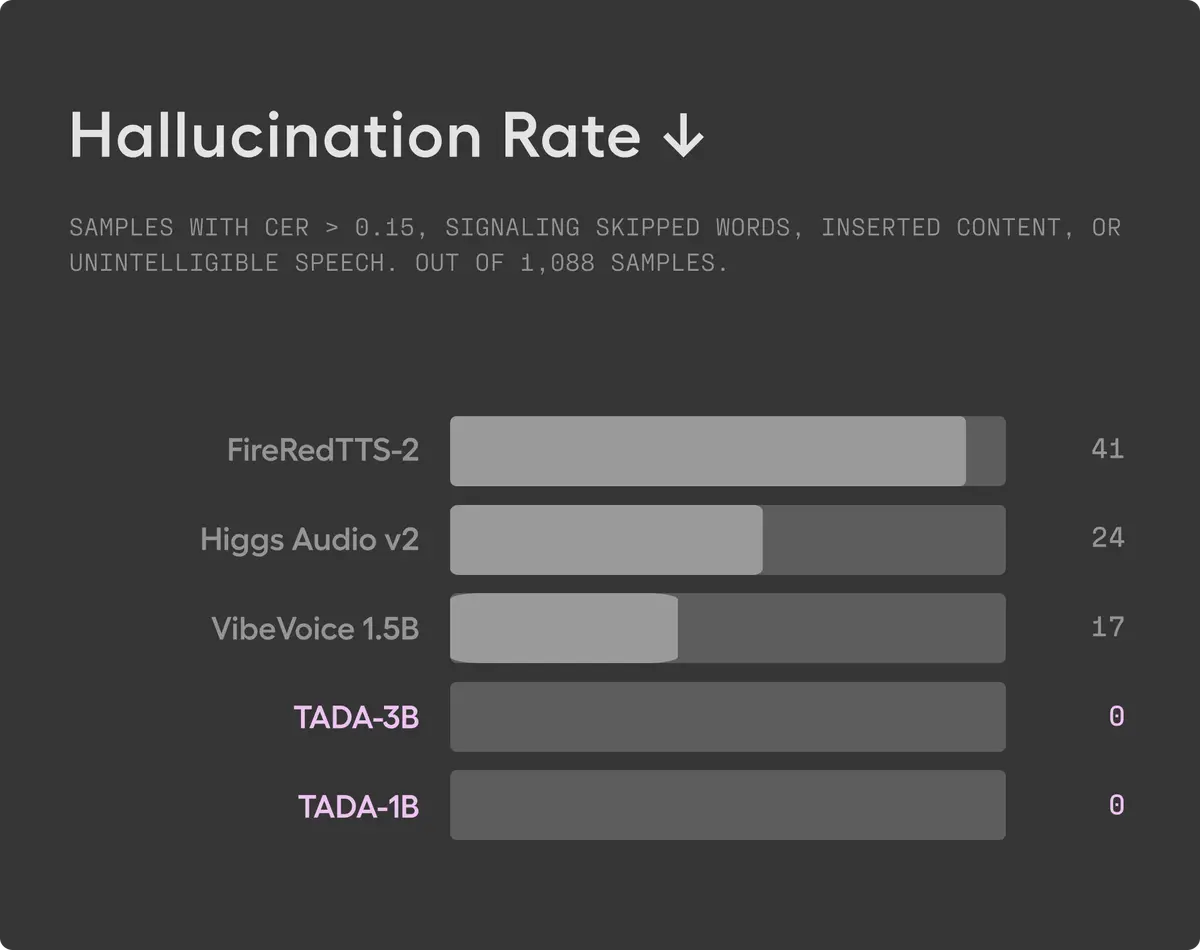
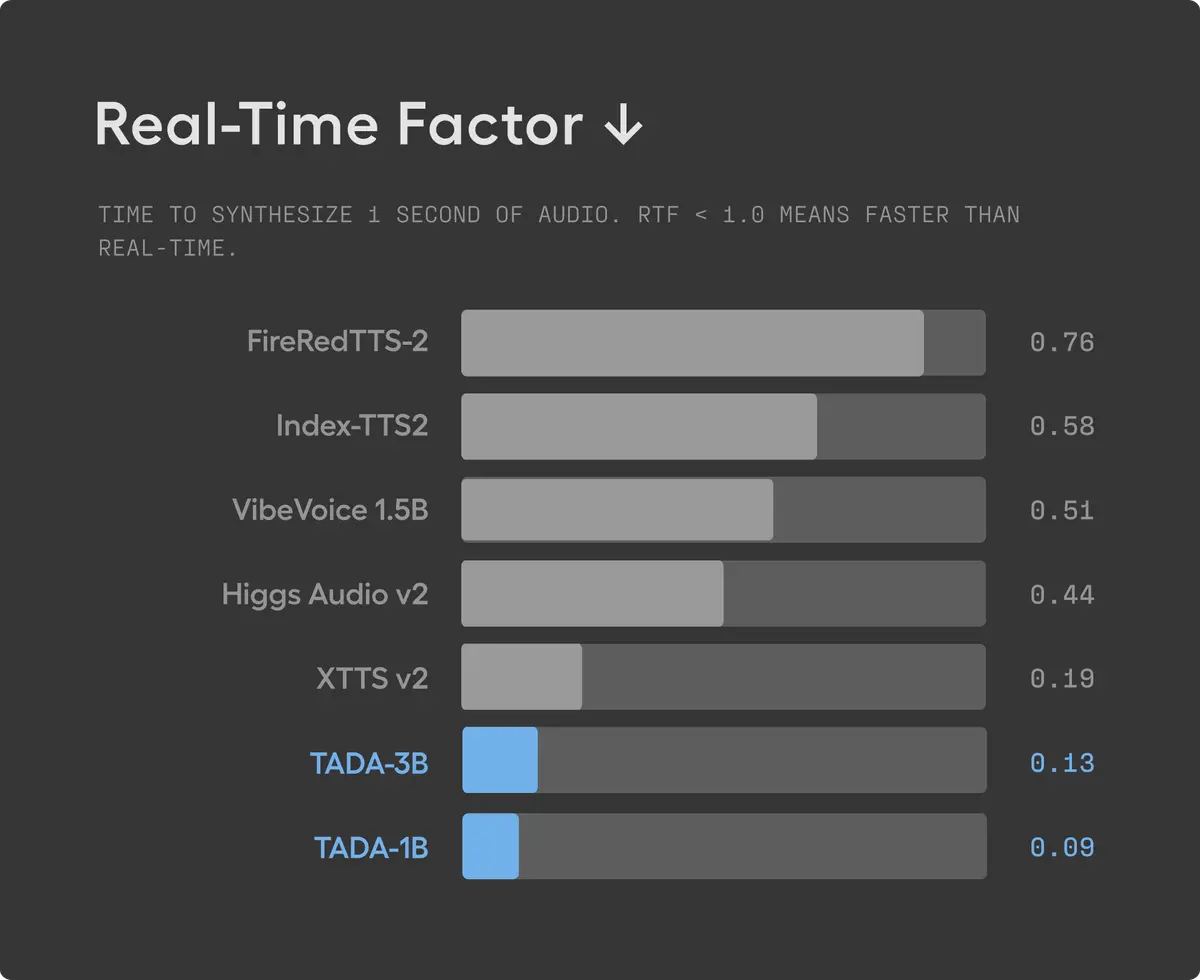
Speed, Quality, and Reliability: What the Numbers Show
Speed
TADA generates speech at a real-time factor (RTF) of 0.09 — meaning it generates audio more than 5x faster than comparable LLM-based TTS systems. This is because it only needs to process 2–3 frames per second of audio, compared to 12.5–75 tokens per second in other approaches.
Hallucinations
A hallucination in TTS means the model says something it wasn't supposed to — skipping words, inserting random content, or producing unintelligible audio. Hume measured this by flagging any sample with a character error rate above 0.15.
According to Hume's testing on 1,000+ samples from the LibriTTSR dataset, TADA produced zero hallucinations. The model was trained on large-scale, real-world data without post-training, and still matched the reliability of models trained on smaller, hand-curated datasets.
Voice Quality
In human evaluation using the EARS dataset (focused on expressive, long-form speech), TADA scored 4.18 out of 5.0 on speaker similarity and 3.78 out of 5.0 on naturalness — placing second overall, ahead of several systems trained on significantly more data.



What You Can Actually Use It For
On-Device Deployment
TADA is lightweight enough to run on mobile phones and edge devices without needing to send data to a cloud server. For developers building voice interfaces, that means lower latency, better user privacy, and no dependency on an external API.
Long-Form Speech
This is where TADA's architecture really stands out. A conventional TTS system typically exhausts its 2,048-token context window — think of this as the model's short-term memory — in about 70 seconds of audio. TADA can fit roughly 700 seconds in the same budget. That's nearly 12 minutes of continuous audio in a single pass, opening the door to audiobooks, extended dialogues, and long-form narration.
High-Stakes Environments
Zero hallucinations in testing suggests fewer errors slipping through in production. Hume specifically calls out healthcare, finance, and education as environments where that reliability matters — places where a model saying the wrong word can cause real problems.
Known Limitations
Hume is transparent about what TADA doesn't yet do well.
Speaker drift on very long generations: Even though the model supports more than 10 minutes of context, the voice can occasionally wander from its original character during long outputs. Hume's current workaround is to reset the context periodically.
The modality gap: When the model generates text and speech together, language quality drops compared to text-only mode. Hume introduced a technique called Speech Free Guidance (SFG) — which blends outputs from text-only and combined text-speech modes — to help, but they acknowledge more work is needed here.
Fine-tuning needed for assistant use cases: The current model is pre-trained for speech continuation. If you want it to behave like a voice assistant, you'll need to fine-tune it further.
Language coverage: The current release supports English plus seven additional languages. Hume says larger models with broader language coverage are in training.
Where to Find It
The model is available now on Hugging Face at HumeAI/tada-1b. The Python package hume-tada is available on PyPI. The accompanying research paper is available at arxiv.org.
Hume's full blog post with technical details and audio demos is at hume.ai/blog/opensource-tada.
Frequently Asked Questions
What does "open source" mean for TADA?
Both the pre-trained model weights and the source code are publicly available. Researchers, developers, and companies can download and use them directly without needing a commercial license or API key.
How is TADA different from other TTS models like ElevenLabs or Bark?
TADA's core difference is its tokenization approach. By aligning text and audio one-to-one, it avoids the speed and reliability tradeoffs that come with managing mismatched token sequences. Most other LLM-based systems have to choose between speed, quality, and reliability — TADA's architecture attempts to address all three simultaneously.
Can TADA run offline on a phone?
According to Hume, yes — TADA is lightweight enough for on-device deployment on mobile phones and edge devices without requiring cloud inference.
What languages does TADA support?
The current release supports English and seven additional languages. Hume says they are training larger models with broader language coverage.
Does TADA require fine-tuning to use?
For basic speech continuation tasks, no. But for assistant-style scenarios — where you want the model to respond conversationally — Hume says further fine-tuning is required.
Bottom Line
TADA is a technically interesting release that addresses real, well-documented problems in LLM-based speech generation — speed, context length, and hallucinations — through a structural change to how text and audio tokens are aligned. The fact that it's fully open source means the research community can verify, build on, and stress-test these claims independently.
The limitations are real, and Hume doesn't hide them. Speaker drift on long outputs and the modality gap are genuine open problems. But for developers who need fast, reliable, on-device speech generation today — especially for long-form content — TADA is worth a close look.