Microsoft BitNet: Run 100B AI Models on Your Laptop CPU (No GPU Needed)
Microsoft's BitNet b1.58 runs 100B parameter AI models on a CPU. 6x faster, 82% less energy. Here's what it is, how it works, and who should use it.


⚡ Helpful Verdict (TL;DR)
Microsoft's BitNet b1.58 and its inference framework bitnet.cpp are genuinely impressive — not hype. The ability to run large language models on a standard CPU, without a GPU, with real speed and energy gains, is a concrete and meaningful shift in who can actually use powerful AI locally.
Key Takeaways
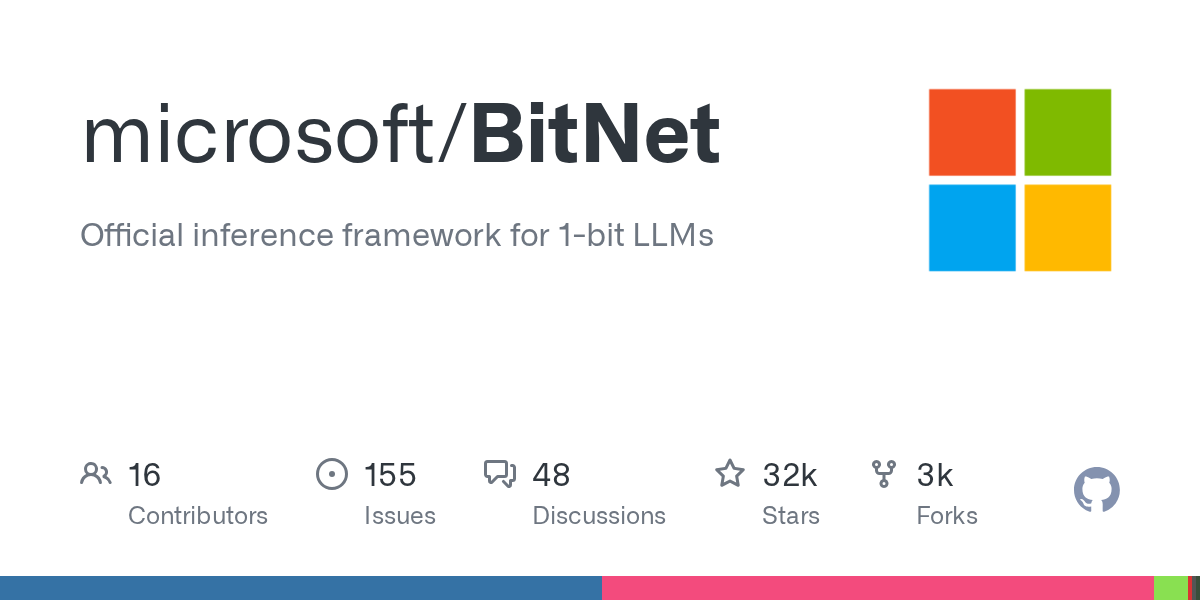
- Microsoft's bitnet.cpp is a fully open-source inference framework for 1-bit LLMs, available on GitHub.
- It can run a 100B parameter model on a single CPU at speeds comparable to human reading (5–7 tokens per second).
- On x86 CPUs, it achieves up to 6.17x faster inference and 82.2% less energy consumption than standard approaches.
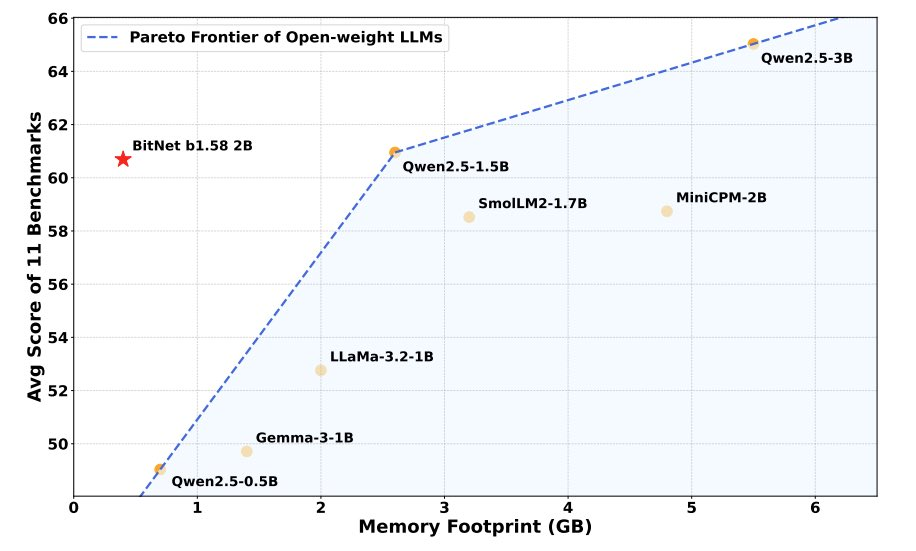
- The official BitNet b1.58 2B4T model outperforms full-precision LLaMA 3.2 1B while using only 0.4GB of memory (vs. 2GB) and running 40% faster.
- It works on Apple M2, x86 desktops, and ARM chips — no cloud, no GPU required.
Why You Should Actually Care About This Right Now
Here's the uncomfortable truth about modern AI: most "open-source" models aren't really open to most people. You can download them, sure. But actually running something like DeepSeek V3 requires hardware that costs roughly $400,000. Even smaller, distilled versions need a GPU worth around $20,000.
For the vast majority of developers and curious users, powerful local AI has been a fantasy — something you either pay a cloud API for, or simply go without.
That's the wall BitNet is trying to knock down. And based on the benchmarks, it's not just chipping away at it.
Microsoft just killed the GPU mafia! 🤯
— Charly Wargnier (@DataChaz) October 3, 2025
They've open-sourced bitnet.cpp, a blazing-fast 1-bit LLM inference framework optimized for CPUs.
This is a major step forward for running large models locally, without expensive GPUs or cloud costs.
Demo app + repo + paper in 🧵 ↓ pic.twitter.com/Vnd2uEJth4
What Is a 1-Bit LLM, Exactly?
To understand why this matters, you need to know how AI models store information. Every AI model is made of millions or billions of weights — think of them like the model's learned instincts, the internal dials that shape how it responds to any input.
Normally, each weight is stored using 16 bits of data (FP16). So a 7 billion parameter model takes up roughly 14GB — more than most laptop GPUs can hold in memory.
One popular fix is quantization — compressing those weights into fewer bits, like squishing a high-res photo into a smaller file. You lose some detail, but the file fits. The problem is, go too far (say, down to 4 bits) and the model starts making noticeably worse predictions.
BitNet takes a radical different approach. Instead of training a full-precision model and then compressing it, BitNet is trained from scratch with 1-bit weights. Each weight can only be one of three values: -1, 0, or +1. That's it. This is why it's technically called "1.58-bit" — three possible values requires slightly more than one binary bit to represent.
Because you're only ever multiplying by -1, 0, or 1, the expensive matrix multiplications that normally require a GPU get replaced with simple addition and subtraction. Your CPU can do that just fine.
Microsoft presents The Era of 1-bit LLMs
— AK (@_akhaliq) February 28, 2024
All Large Language Models are in 1.58 Bits
Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single… pic.twitter.com/2PlQ8ePLDR
The Technical Story: From Paper to Real Framework
The idea wasn't born yesterday. Microsoft Research first proposed 1-bit transformers in an October 2023 paper, "BitNet: Scaling 1-Bit Transformers for Large Language Models." The follow-up paper in February 2024 — "The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits" — introduced the ternary weight system and showed it could match full-precision models in real benchmarks.
But a research paper isn't a product. The real moment came with the release of bitnet.cpp, the official inference framework, and then the BitNet b1.58 2B4T model on Hugging Face — a 2.4 billion parameter model trained on 4 trillion tokens, ready to download and run.
The framework itself is built on top of llama.cpp, the beloved open-source project that first made running LLMs on consumer hardware practical. Microsoft's team added optimized kernel implementations specifically for 1-bit arithmetic, with parallel processing and embedding quantization support.
The numbers from their testing are hard to dismiss:
- ARM CPUs: 1.37x to 5.07x speedup, 55.4% to 70.0% less energy
- x86 CPUs: 2.37x to 6.17x speedup, 71.9% to 82.2% less energy
- 100B model on a single CPU: runs at 5–7 tokens per second — roughly the pace you read text
A January 2026 update added parallel kernel implementations with configurable tiling, pushing an additional 1.15x to 2.1x speedup on top of those already impressive gains. GPU inference support also landed in May 2025, and NPU support is reportedly coming next.
The 2B Model:
The real-world test case the community keeps pointing to is BitNet b1.58 2B4T — a model small enough to actually use daily, but smart enough to matter.
According to Microsoft's benchmarks, it outperforms the full-precision LLaMA 3.2 1B model on standard tasks, while running in just 0.4GB of memory instead of 2GB, and processing tokens 40% faster. And yes, that includes running on an Apple M2 chip.
The real win here isn't just "smaller model, less memory." It's that a 1-bit model trained natively at this scale performs comparably to a standard model that's genuinely larger. That's the bet BitNet's research is making — that ternary weights, trained right from the start, don't sacrifice much intelligence at all.
How to Try It Yourself
Getting started requires Python 3.9+, CMake 3.22+, and Clang 18+. Microsoft recommends using Conda to manage the environment. The full setup guide is on the official GitHub repo.
The quick-start flow looks like this:
git clone --recursive https://github.com/microsoft/BitNet.git
cd BitNet
conda create -n bitnet-cpp python=3.9
conda activate bitnet-cpp
pip install -r requirements.txt
huggingface-cli download microsoft/BitNet-b1.58-2B-4T-gguf --local-dir models/BitNet-b1.58-2B-4T
python setup_env.py -md models/BitNet-b1.58-2B-4T -q i2_s
python run_inference.py -m models/BitNet-b1.58-2B-4T/ggml-model-i2_s.gguf -p "You are a helpful assistant" -cnvDon't want to build from source? There's a live web demo you can try right now in your browser.
Community Buzz: "GPU Mafia Killer" Energy
AI Twitter has been in full enthusiasm mode about this — and the framing has been consistent. The phrase "GPU mafia" keeps appearing, a tongue-in-cheek dig at the dependency on expensive Nvidia hardware that has defined AI deployment for years. Whether or not that's an overstatement, the emotional point resonates.
What's interesting is that two distinct audiences are excited for different reasons. Developers care about the raw performance numbers and CPU compatibility. Privacy-focused users care that fully local inference means your prompts never leave your machine. No API calls. No data logging. No subscription.
The Apple Silicon angle has also struck a nerve. The fact that M2 is explicitly called out as a supported platform signals to a huge developer audience — one that has largely been priced out of local GPU inference — that this is finally for them.
Microsoft just a 1-bit LLM with 2B parameters that can run on CPUs like Apple M2.
— Shubham Saboo (@Saboo_Shubham_) April 18, 2025
BitNet b1.58 2B4T outperforms fp LLaMA 3.2 1B while using only 0.4GB memory versus 2GB and processes tokens 40% faster.
100% opensource. pic.twitter.com/kTeqTs6PHd
This is a rather big deal for running large AI models!
— Brian Roemmele (@BrianRoemmele) September 5, 2025
Microsoft has open sourced a 1-bit LLM inference framework called bitnet.cpp
It uses 82.2% less energy on CPUs with no GPU needed 6.17x faster inference. Full support for Llama3, Falcon3, BitNet. https://t.co/AdmZecZVkB
Globally, the excitement isn't confined to English-speaking AI circles either. Japanese AI community members have picked this up enthusiastically, with commentary noting that local AI inference has crossed into a new level of practicality.
But if I'm being honest: the current discourse is missing critical analysis. Nobody in the hype cycle is seriously discussing task-specific quality degradation, edge cases where ternary weights underperform, or how this scales across diverse real-world prompts. The benchmarks look good — but they're Microsoft's benchmarks. Independent reproducibility tests will tell a more complete story.
Final Advice: Who Should Use This?
Use BitNet if you:
- Want to run a capable AI model locally without buying a GPU
- Are working on an Apple M2, M3, or modern x86 laptop or desktop
- Care about data privacy and want zero API exposure
- Are a developer exploring edge AI or on-device inference for applications
- Want to experiment with a legitimately novel architecture, not just a quantized version of an existing model
Hold off or stay cautious if you:
- Need state-of-the-art reasoning or coding performance — the 2B model is good, but it's still a 2B model
- Are running production workloads where benchmark reproducibility hasn't been independently verified
- Expect this to replace a full 70B+ model experience on complex tasks
The broader trajectory here is what's exciting. BitNet b1.58 2B4T is a proof of concept at scale. If native 1-bit training continues to hold up as models grow larger, the economics of local AI inference change fundamentally. That's not hype — that's a reasonable reading of what the benchmarks are showing.
Start with the GitHub repo, try the live demo, and grab the model from Hugging Face. It's all free.